什么是持久化:
redis所有数据保存在内存中,对数据的更新将异步地保存到磁盘上。
方式:快照(MySQL Dump、Redis RDB),写日志(MySQL Binlog、Hbase Hlog、Redis AOF)
什么是RDB:
RBD持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)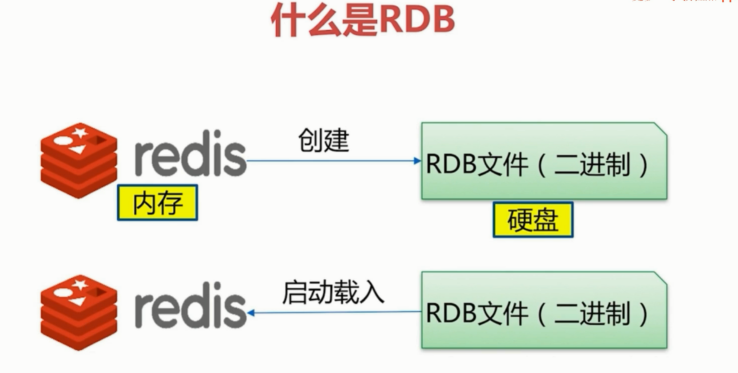
RBD的三种方式:
save(同步),bgsave(异步),自动
save:复杂度O(n),如果旧文件存在,旧文件将被新文件替换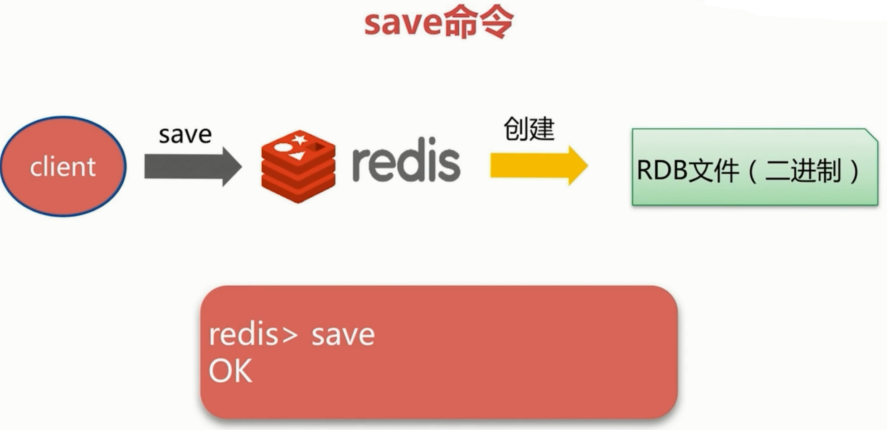
bgsave: 同save,但它是异步执行的,将fork出一个进程执行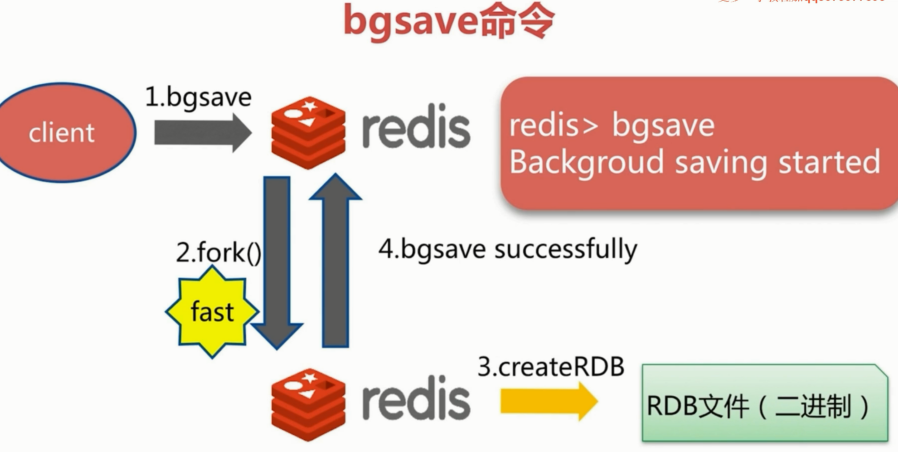
对比: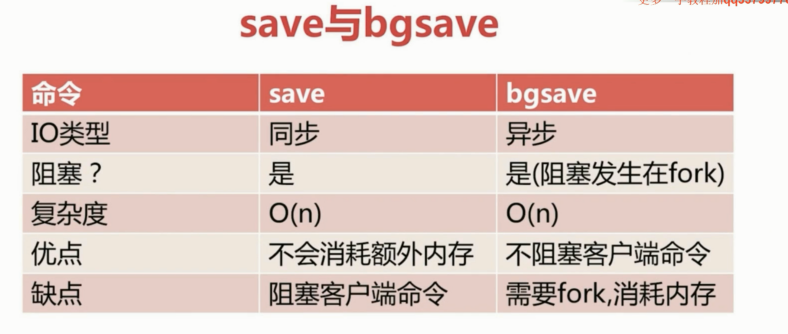
自动策略:在配置中修改,
rdbcompression yes #存储至本地数据库时(持久化到rdb文件)是否压缩数据,默认为yes
dbfilename dump.rdb #本地持久化数据库文件名,默认值为dump.rdb
dir ./ #储存工作目录 AOF文件也会存放在这个目录下面
stop-writes-on-bgsave-error yes #出错时是否停止备份,一般yes
rdbcompression yes #备份时是否压缩,一般yes
rdbchecksum #是否采用效验的方式 一般yes
其他触发机制:全量复制、debug reload、shutdown。
总结:
1.RDB是Redis内存到硬盘的快照,用于持久化
2.save通常会阻塞Redis
3.bgsave不会阻塞Redis,但是会fork新进程
4.save自动配置满足任一就会被执行
5.有些触发机制不容忽视
AOF机制:
RDB有什么问题:
耗时、耗性能: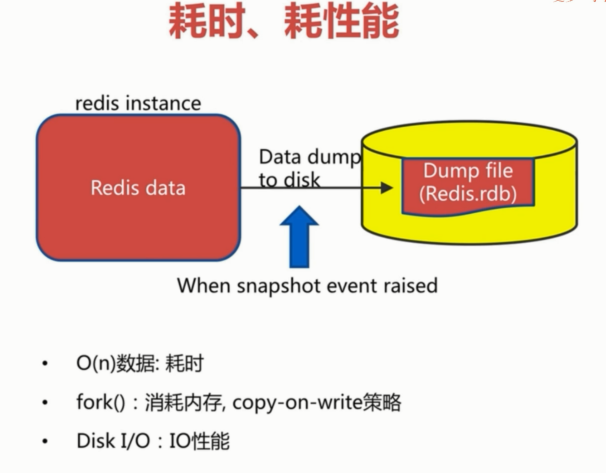
不可控,会丢失数据: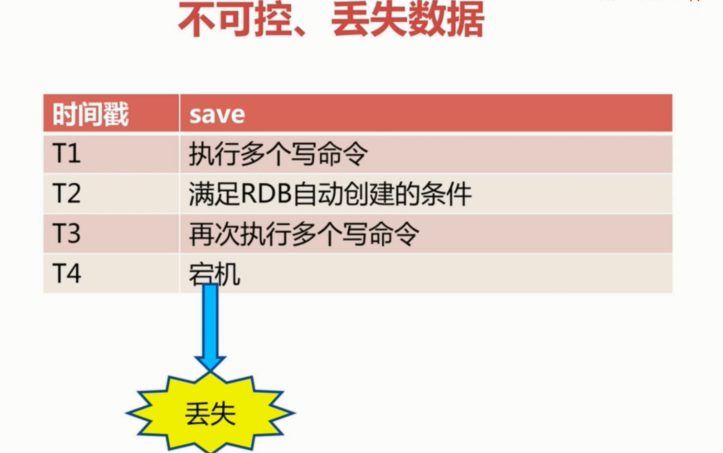
AOF原理: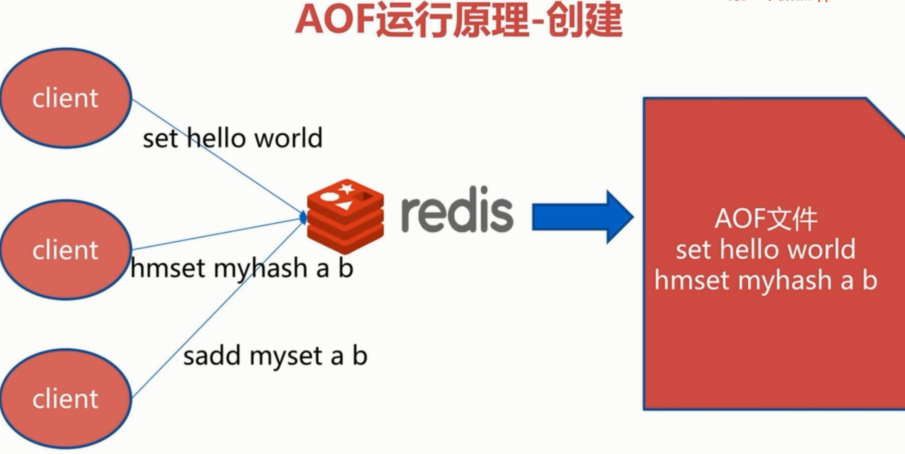
三种策略:
always: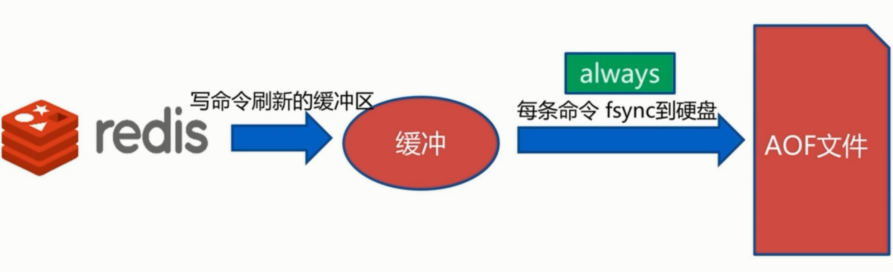
everysec: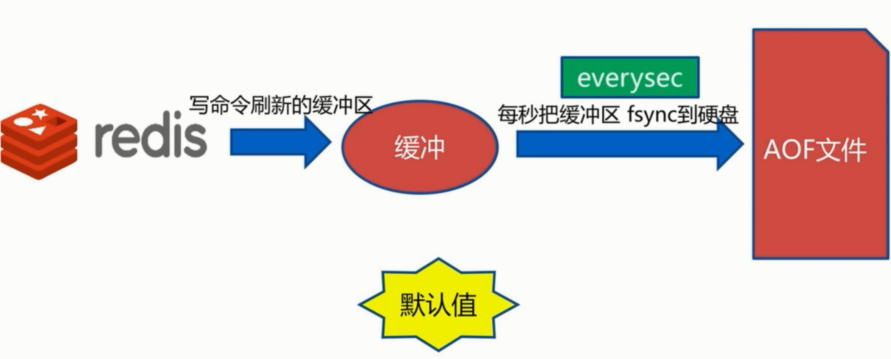
no:
对比
原理:
AOF重写作用:
减少硬盘占用量
加速恢复速度
实现方式:
bgrewriteaof: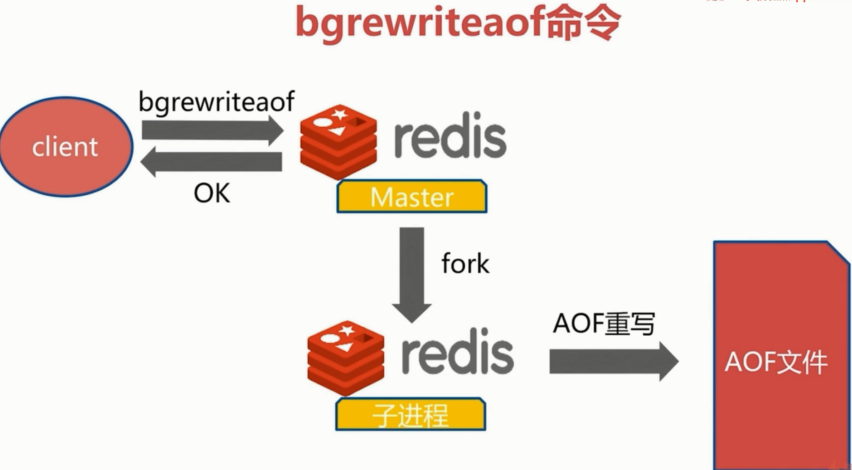
AOF重写配置:
auto-aof-rewrite-min-size:AOF文件重写需要的尺寸,如aof文件文件达到某个大小,开始重写。
auwo-aof-rewrite-percentage :AOF文件增长率,假设该值为10,如果AOF重写后文件100M,增长到110M,则重写
统计名:
aof_current_size:AOF当前尺寸(单位:字节)
aof_base_size:AOF上次启动和重写的尺寸(单位:字节)
触发时机(同时满足):
aof_current_size>auto-aof-rewrite-min-size
aof_current_size-aof_base_size/aof_base_size>auto-aof-rewrite-percentage
重写流程: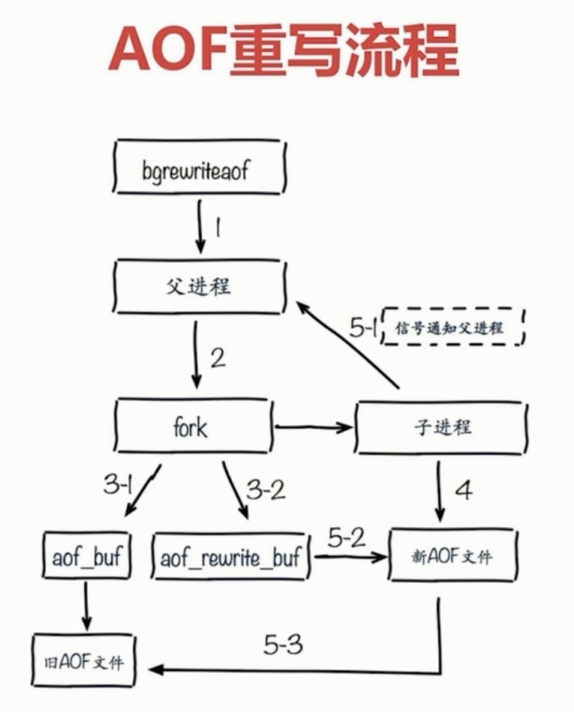
配置:
appendonly yes #是否开启AOF
appendfilename 'appendonly-${port}.aof' #AOF文件名称
appendfsync everysec #AOF策略
dir /bigdiskpath #AOF文件目录
no-appendfsync-on-rewrite yes #写下
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size-64mb
关于no-appendfsync-on-rewrite配置:bgrewriteaof机制,在一个子进程中进行AOF的重写,从而不阻塞主进程对其余命令的处理,同时解决了aof文件过大问题。
现在问题出现了,同时在执行bgrewriteaof操作和主进程写AOF文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写AOF文件的时候出现阻塞的情形,现在no-appendfsync-on-rewrite参数出场了。如果该参数设置为no,是最安全的方式,不会丢失数据,但是要忍受阻塞的问题。如果设置为yes呢?这就相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?在linux的操作系统的默认设置下,最多会丢失30s的数据。
因此,如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
2种持久化的选择:
对比: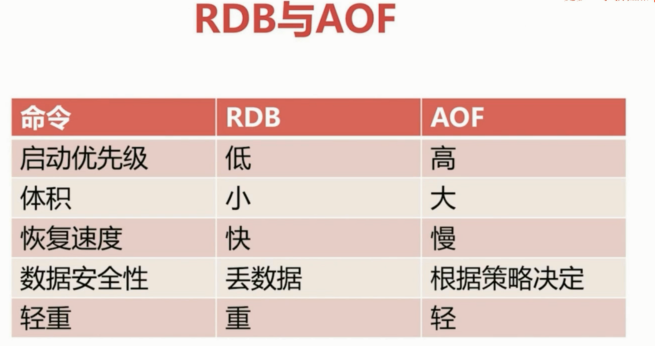
PS:这里的“轻/重”指的是消耗资源(I/O等)的开销。
RDB最佳策略:“关”、集中管理、主从,从开?
AOF最佳策略:“开”:缓存和存储、AOF重写集中管理,everysec。
最佳:小分片,缓存或者存储,监控(硬盘、内存、负载、网络)、足够的内存
具体可看这篇文章:
出自《Redis 中文文档》
https://wizardforcel.gitbooks.io/redis-doc/content/doc/6.html
开发运维常见问题:
fork操作:
是一个同步操作,与内存量息息相关:内存越大,耗时越长(与机器类型有关)、
info:last_fork_usec上一次所消耗的微妙数,
1.有限使用物理机或者高效支持fork操作的虚拟化技术
2.控制redis实例最大可用内存:maxmemory
3.合理配置linux内存配置策略:vm.overcommit_memory=1 #默认为0,当发现没有足够内存做内存分配的时候,就不去分配。
4.降低fork频率:例如放宽AOF重写触发时机,不必要的全量复制
进程外开销
子进程开销和优化:
CPU:RDB和AOF文件生成,属于CPU密集型 优化:不做CPU绑定,和不CPU密集型部署
内存:fork内存开销,copy-on-wirte, 优化:echo never >/sys/kernel/mm/transparent_hugepage/enabled
硬盘:AOF和RDB文件写入,可以结合iostat、iotop分析
不要和高硬盘负载服务部署一起:存储服务、消息队列等
no-appendfsync-on-rewrite=yes
根据写入量决定磁盘类型:例如ssd
单机多实例持久化文件目录可以考虑分盘
AOF追加阻塞:
可通过日志或者info Persistence查看(显示的是累加的数量),根据实际情况优化。